Pamięć podręczna (Cache)
Cache (pamięć podręczna) to ogólne pojęcie — oznacza mechanizm przechowywania danych w szybkim miejscu (RAM, SSD) w celu skrócenia czasu dostępu. W architekturach i projektowaniu systemów mamy różne strategie korzystania z cache, m.in.:
- Cache-aside (lazy loading) – aplikacja sama sprawdza cache, a jeśli tam nie ma danych, pobiera je z bazy i zapisuje do cache.
- Read-through – aplikacja nie pobiera danych sama z bazy, tylko zawsze pyta cache, a ten w razie potrzeby sam pobiera dane z bazy (cache jest pośrednikiem).
- Write-through – zapis do cache powoduje automatyczny zapis do bazy.
- Write-back – zapis trafia najpierw do cache, a do bazy dopiero po pewnym czasie lub przy synchronizacji.
| Strategia | Opis | Zalety | Wady | Przykłady użycia |
|---|---|---|---|---|
| 1 | Aplikacja sama sprawdza cache; jeśli brak danych, pobiera je z bazy i zapisuje do cache. | Prosta implementacja; kontrola nad tym, co trafia do cache; mniejsze obciążenie cache. | Ryzyko "cold start" (puste cache = wolne pierwsze zapytania); wymaga dodatkowej logiki w aplikacji. | Dane rzadko zmieniane; scenariusze, w których aplikacja ma pełną kontrolę nad odczytem i zapisem. |
| 2 | Aplikacja zawsze pyta cache; cache w razie braku danych sam pobiera je z bazy. | Spójny punkt dostępu; brak konieczności pisania logiki pobierania danych w aplikacji. | Wydajność zależy od implementacji cache; większa złożoność systemu cache. | Systemy o dużej liczbie odczytów, np. Redis/Memcached z backendem w bazie SQL/NoSQL. |
| 3 | Zapis do cache powoduje automatyczny zapis do bazy (synchronizacja w czasie rzeczywistym). | Zapewnia spójność danych między cache i bazą; prosta obsługa odczytów po zapisie. | Większa latencja zapisu (operacje do cache i bazy); obciążenie bazy. | Systemy wymagające wysokiej spójności, np. dane finansowe, systemy rezerwacji. |
| 4 | Zapis trafia najpierw do cache, a do bazy dopiero po pewnym czasie lub przy synchronizacji. | Niska latencja zapisu; mniejsze obciążenie bazy; możliwość grupowania zapisów. | Ryzyko utraty danych przy awarii cache; potencjalna niespójność między cache i bazą. | Scenariusze z dużą liczbą zapisów, w których opóźnienie synchronizacji danych jest akceptowalne. |
- Cache poisoning – wstrzyknięcie lub podmiana danych w cache (np. HTTP Cache Poisoning, DNS Cache Poisoning), co może skutkować podaniem użytkownikom spreparowanych treści.
- Cache deception – zmuszenie aplikacji/webserwera do zapisania w cache wrażliwych danych, które normalnie nie powinny być buforowane, a następnie ich odczytanie.
- Session caching – jeśli sesje lub tokeny są przechowywane w cache (np. Redis, Memcached) bez odpowiedniego TTL i zabezpieczeń, może dojść do kradzieży sesji.
- Side-channel attacks – analiza czasu odpowiedzi z cache vs. z bazy danych może ujawniać istnienie danych (np. różnica czasu przy IDOR).
- Cache-aside (lazy loading) – aplikacja sama ładuje dane do cache; ryzyko pojawia się, jeśli dane w cache nie są czyszczone po zmianach lub mają zbyt długi TTL.
- Read-through – aplikacja komunikuje się tylko z warstwą cache; kompromitacja cache = dostęp do wszystkich danych.
- Write-through / Write-back – manipulacja cache może wpłynąć na dane w bazie (np. nieautoryzowane nadpisanie wartości).
- HTTP caching – nagłówki Cache-Control, ETag, Vary, Expires muszą być prawidłowo ustawione, aby uniknąć ujawnienia prywatnych danych innym użytkownikom.
- In-memory caches (Redis, Memcached) – powinny być dostępne tylko z sieci wewnętrznej, zabezpieczone hasłem i TLS; brak zabezpieczeń = przejęcie pełnych danych.
- Przeglądarkowy cache – nie wolno buforować stron zawierających dane wrażliwe (ustaw Cache-Control: no-store dla stron logowania, paneli admina itp.).
- Stosuj TTL (Time-to-Live) i mechanizmy wygaszania danych.
- Ograniczaj dostęp do warstwy cache (ACL, firewalle, VPN).
- Waliduj dane z cache przed ich użyciem, jeśli źródło może być potencjalnie skażone.
- Ustawiaj odpowiednie nagłówki HTTP, aby unikać buforowania prywatnych danych w przeglądarkach lub CDN.
- Monitoruj i loguj dostęp do cache.
Cache-aside (lazy loading)
Cache-Aside Pattern to popularna strategia buforowania, w której pamięć podręczna (cache) i baza danych są niezależne, a zarządzanie nimi spoczywa po stronie kodu aplikacji. Oznacza to, że aplikacja sama odpowiada za:
- sprawdzanie, czy dane znajdują się w cache,
- ładowanie ich z bazy danych, jeśli ich tam nie ma,
- aktualizację lub unieważnianie danych w cache po zmianach w bazie.
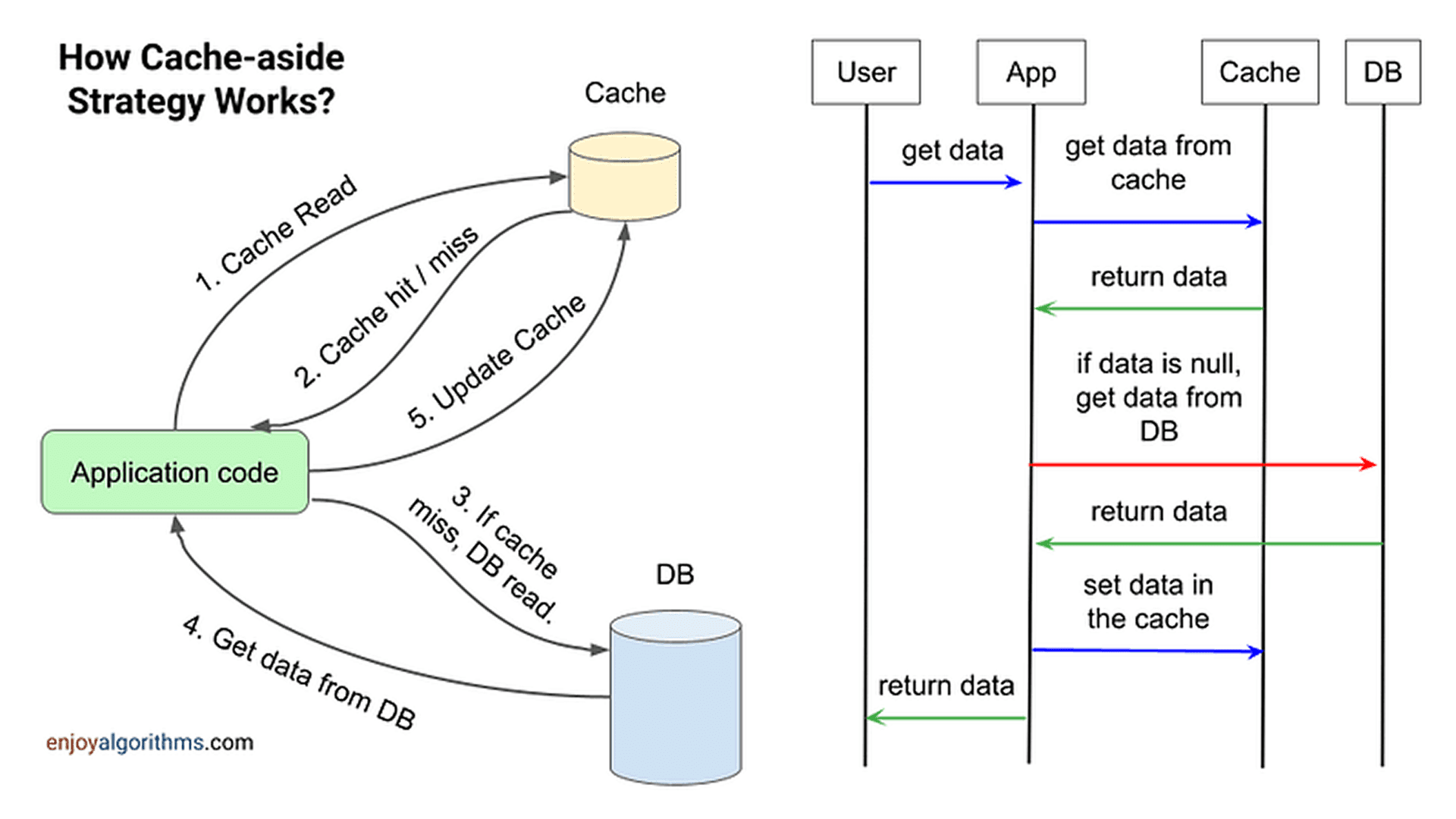
- Aplikacja sprawdza, czy dane są w cache (cache hit/miss).
- Jeśli dane są w cache – zwraca je do użytkownika.
- Jeśli danych nie ma w cache – pobiera je z bazy danych, zapisuje w cache i dopiero potem zwraca do użytkownika.
- Aktualizacja bazy danych + unieważnienie danych w cache (write-around) – po zmianie danych w bazie usuwa się ich kopię z cache, aby kolejne zapytanie wymusiło ponowne załadowanie aktualnych danych.
- Aktualizacja bazy danych + aktualizacja danych w cache (write-through) – po zmianie danych w bazie natychmiast aktualizuje się dane w cache, aby zawsze były aktualne.
Istnieją dwa podejścia:
- Duża kontrola nad tym, co i na jak długo trafia do cache.
- Elastyczność w dostosowywaniu strategii do potrzeb aplikacji.
- Odporność na awarie cache – aplikacja może nadal pobierać dane z bazy.
- Efektywne wykorzystanie cache – przechowuje tylko to, co aplikacja faktycznie pobiera.
- Możliwość łatwego skalowania i modyfikacji warstwy cache.
Istnieją dwa podejścia:
- Większa złożoność kodu – konieczność samodzielnego zarządzania cache.
- Możliwość niespójności danych między cache a bazą (np. jeśli dane w bazie zmienią się poza aplikacją).
- Częste cache miss przy danych często zmienianych.
- W systemach rozproszonych – ryzyko niespójności danych między lokalnymi instancjami cache.
Istnieją dwa podejścia:
- Każda instancja aplikacji może przechowywać własną kopię danych w pamięci.
- Problem pojawia się, gdy instancje korzystają z tych samych danych – mogą się one rozjechać.
- Rozwiązaniem jest cache rozproszony (np. Redis), który zapewnia spójność danych we wszystkich instancjach.
Istnieją dwa podejścia:
- Każdy wpis w cache może mieć czas życia (TTL – Time To Live), po którym jest usuwany.
- Zbyt niski TTL – częste cache miss, większe obciążenie bazy.
- Zbyt wysoki TTL – ryzyko zwracania nieaktualnych danych.
- TTL należy dobrać w zależności od charakteru danych – rzadko zmieniane mogą mieć dłuższy czas życia.
Istnieją dwa podejścia:
Read-through cache
Read-Through Cache to strategia buforowania, w której aplikacja komunikuje się wyłącznie z warstwą pamięci podręcznej (cache), a ta — jeśli zajdzie potrzeba — pobiera dane z bazy danych w imieniu aplikacji. W odróżnieniu od wzorca Cache-Aside, logika pobierania i aktualizowania cache znajduje się w samym systemie cache, a nie w kodzie aplikacji.
LRU (Least Recently Used) – polityka zarządzania zawartością cache, często używana w read-through. Gdy cache jest pełny, usuwa elementy, które były najrzadziej używane w ostatnim czasie, aby zwolnić miejsce na nowe dane.
- Logika odczytu z DB jest po stronie systemu cache, a nie aplikacji.
- Aplikacja komunikuje się tylko z warstwą cache, która w przypadku cache miss pobiera dane z bazy i zapisuje je w pamięci.
- Popularne w systemach typu Redis, Memcached w trybie read-through.
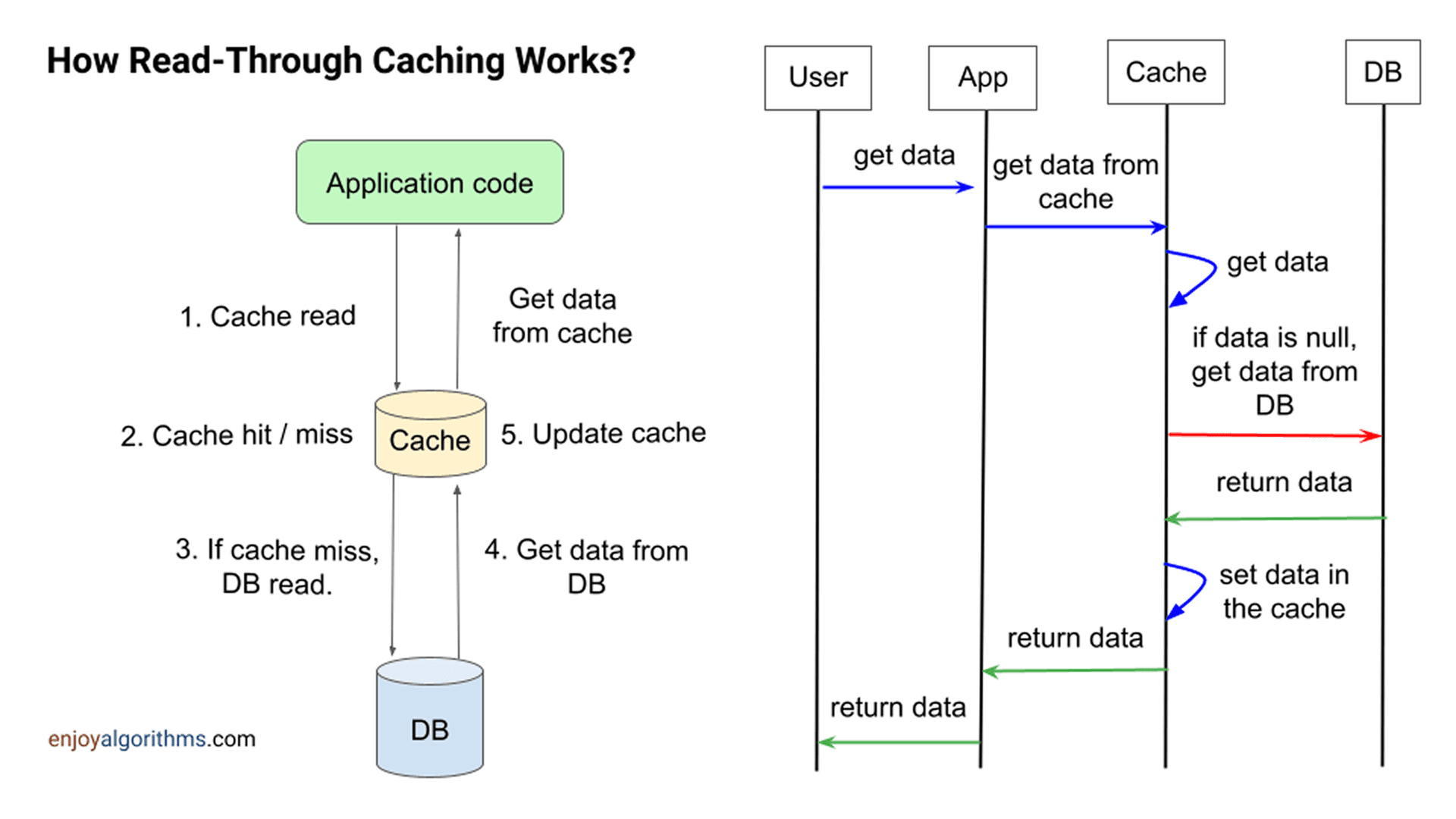
- Aplikacja wysyła zapytanie do cache.
- Cache hit – jeśli dane są w pamięci podręcznej, zostają zwrócone natychmiast.
- Cache miss – jeśli danych nie ma w cache:
- Cache pobiera dane z bazy danych.
- Dane są zapisywane w pamięci podręcznej.
- Zwracane są do aplikacji.
- Przy kolejnych zapytaniach te same dane zostaną zwrócone z cache, co zwiększa szybkość i zmniejsza obciążenie bazy.
- Niższe opóźnienia odczytu dla często używanych danych, szczególnie gdy źródło jest geograficznie odległe.
- Automatyczna spójność danych przy zastosowaniu strategii zapisu typu write-through.
- Możliwość lazy loadingu przy zastosowaniu write-around — dane ładowane są tylko wtedy, gdy faktycznie są potrzebne.
- Redukcja liczby zapytań do bazy danych, gdy dane znajdują się w cache.
- Możliwość automatycznego przeładowania danych po wygaśnięciu TTL lub zmianie w bazie.
- Upraszcza kod aplikacji — logika obsługi cache jest w warstwie cache, a nie w aplikacji.
- W przypadku awarii węzła cache, można go szybko odtworzyć (chociaż początkowo wystąpią częstsze cache miss).
- Cache miss przy pierwszym żądaniu lub po wygaśnięciu TTL powoduje dodatkowe opóźnienie (trzy kroki: sprawdzenie cache → pobranie z DB → zapisanie do cache).
- Ryzyko buforowania rzadko używanych danych, co może zajmować cenne miejsce w cache kosztem danych często używanych.
- Możliwość niespójności danych między cache a bazą, jeśli wpis w cache nie wygaśnie, a dane w bazie się zmienią (konieczność konfiguracji odpowiednich strategii wygaszania lub write-through).
- Cache stampede – jednoczesne wygaśnięcie wielu wpisów może wywołać lawinę zapytań do bazy.
- Write-Through – zapis do cache i bazy równocześnie (większa spójność, większe opóźnienie zapisu).
- Write-Around – zapis tylko do bazy, cache aktualizowany przy pierwszym odczycie (mniejsze obciążenie cache, ale pierwszy odczyt wolniejszy).
- Write-Back / Write-Behind – zapis początkowo tylko w cache, baza aktualizowana asynchronicznie (mniejsze opóźnienie zapisu, ale ryzyko utraty danych przy awarii cache).
- Dobranie optymalnego TTL (czas życia danych).
- Zapobieganie cache stampede (np. przez request coalescing lub locking).
- Ustalenie optymalnej polityki wysuwania danych (LRU, LFU itp.).
- Skalowanie w środowisku rozproszonym.
- Monitorowanie spójności danych między cache a bazą.
Write-through cache
Strategia write-through jest podobna do wzorca read-through, ale z kluczową różnicą – cache jest również odpowiedzialny za obsługę operacji zapisu. Gdy aplikacja chce zapisać dane:
- Najpierw zapisuje je do pamięci podręcznej (cache).
- System cache synchronizuje dane z główną bazą danych w sposób synchroniczny.
Dzięki temu pamięć podręczna znajduje się pomiędzy aplikacją a bazą danych jako warstwa pośrednia, a operacja zapisu zawsze przechodzi przez cache do bazy danych. Operacja uznawana jest za zakończoną dopiero, gdy zapis do obu warstw (cache i DB) się powiedzie.
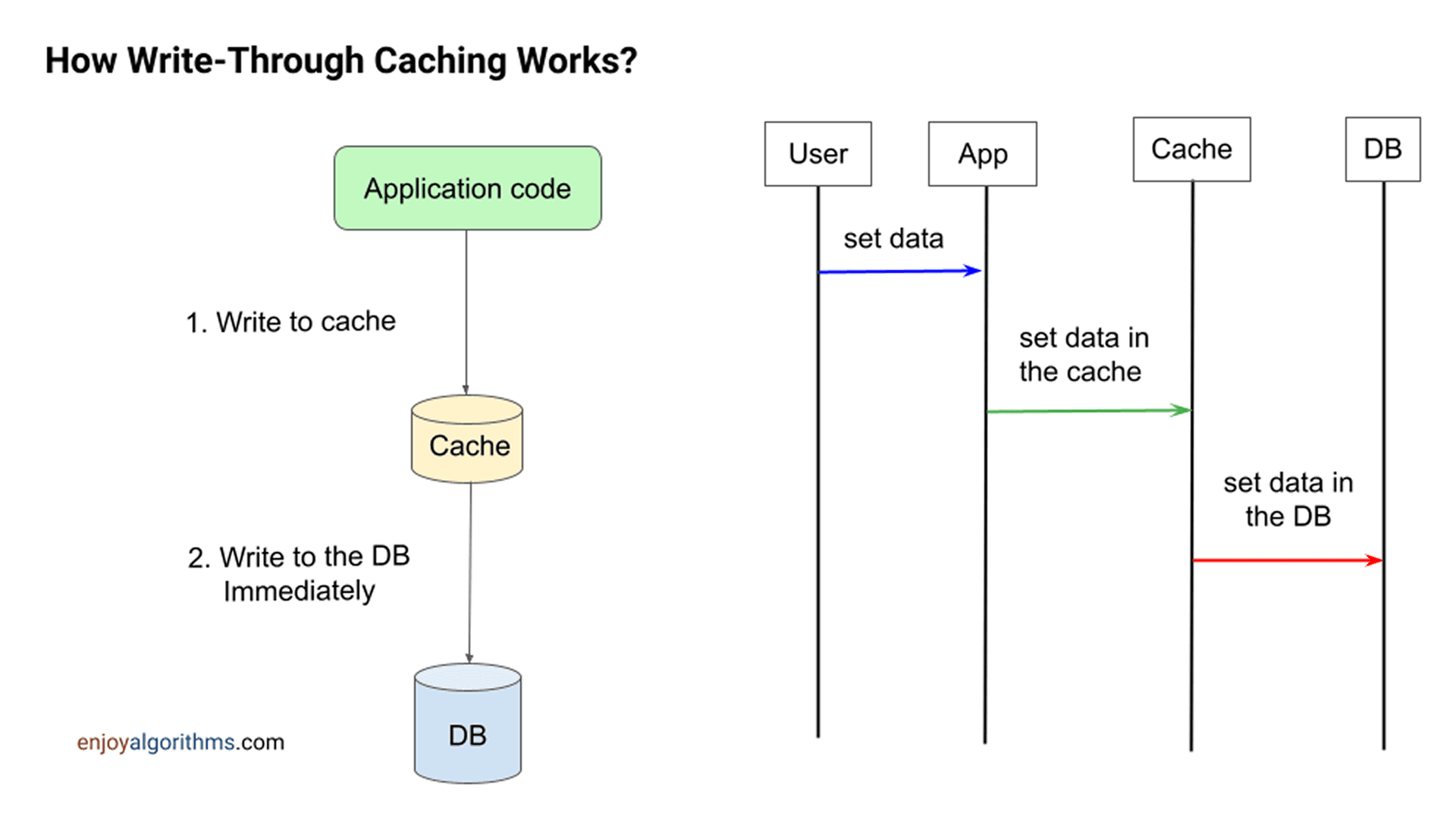
- Aplikacja sprawdza cache – jeśli dane są dostępne (cache hit), są odczytywane bezpośrednio.
- Jeśli danych nie ma (cache miss), są pobierane z bazy danych, zapisywane w cache i zwracane do aplikacji.
- Zawsze aktualne dane w cache (brak ryzyka, że będą starsze niż w bazie).
- Szybkie odczyty dzięki temu, że cache jest zawsze wypełniony aktualnymi danymi.
- Zmniejszone ryzyko utraty danych w przypadku awarii systemu – baza i cache są zsynchronizowane.
- Przywracanie po awarii jest łatwiejsze, bo obie warstwy są w zgodzie.
- Większe opóźnienia zapisu – zapis musi być wykonany w cache i w bazie (dwie operacje).
- Przy częstych zapisach obciążenie bazy może być duże, a cache może być „zaśmiecany” danymi rzadko odczytywanych elementów.
- W przypadku awarii cache cały system może działać wolniej (bo wszystkie operacje muszą przechodzić przez bazę).
- Strategia jest mniej opłacalna w systemach z dużą liczbą zapisów i małą liczbą odczytów tych samych danych.
Konieczność strategii usuwania danych (Eviction Strategy).
Mimo że cache jest spójny z bazą, nadal trzeba stosować strategie usuwania danych, np.:
- TTL (Time-To-Live) – ogranicza czas życia danych w cache, co zapobiega jego przepełnieniu.
- LRU (Least Recently Used) lub LFU (Least Frequently Used) – pozwala usuwać rzadko używane dane, aby cache zawierał tylko najbardziej potrzebne.
Write-back
Strategia Write-Behind (znana też jako Write-Back) jest alternatywą dla Write-Through, stworzoną w celu zmniejszenia opóźnień zapisu. W Write-Through każda operacja zapisu jest synchronizowana zarówno w pamięci podręcznej, jak i w bazie danych, co może powodować wysoką latencję. W Write-Behind dane są najpierw zapisywane do pamięci podręcznej, a ich zapis do bazy danych następuje asynchronicznie po pewnym czasie.
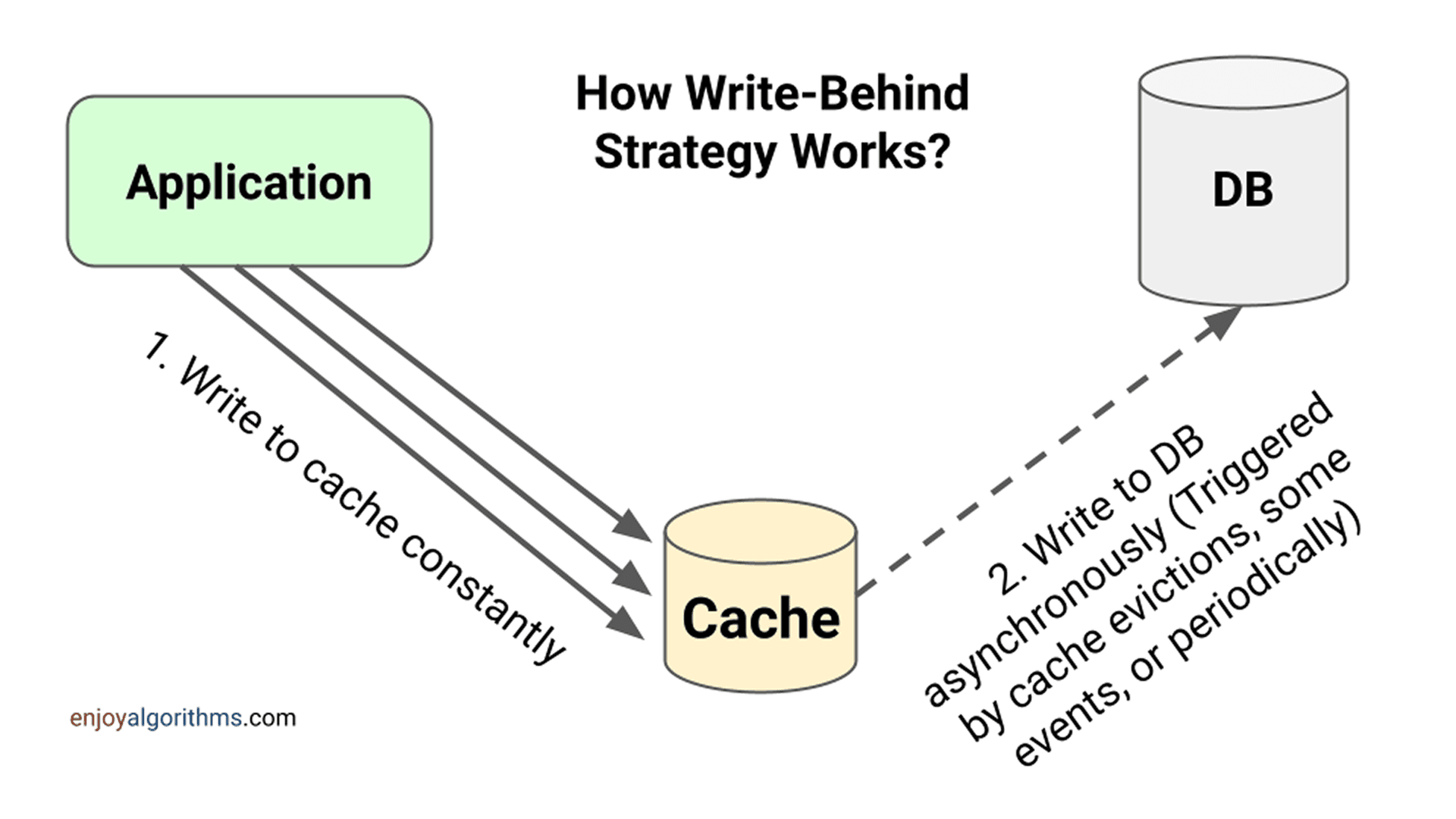
- Aplikacja zapisuje dane w pamięci podręcznej (cache).
- Cache przyjmuje zapis natychmiast i potwierdza go aplikacji.
- Zapis do bazy danych jest wykonywany z opóźnieniem — może być wywołany przez:
- harmonogram (np. co określony czas),
- określoną liczbę zmian,
- zdarzenia, takie jak usunięcie elementu z cache.
- Niższa latencja zapisu — aplikacja nie czeka na aktualizację bazy danych.
- Lepsza wydajność przy dużym obciążeniu zapisami (write-heavy workloads).
- Możliwość łączenia z innymi strategiami (np. Read-Through) dla zoptymalizowania operacji odczytu i zapisu.
- Redukcja obciążenia bazy danych — zapisy grupowane i wykonywane rzadziej.
- Rate limiting — ograniczenie liczby operacji zapisu w danym czasie, aby uniknąć przeciążenia.
- Batching i coalescing — łączenie wielu zapisów w jeden lub scalanie kilku aktualizacji tego samego rekordu.
- Time shifting — planowanie zapisów w mniej obciążonych okresach działania bazy.
- Ryzyko niespójności danych — baza może chwilowo zawierać starsze dane niż cache.
- Potencjalna utrata danych w przypadku awarii cache przed zapisem do bazy.
- Wymaga dodatkowych mechanizmów zapewniających niezawodność, np. kolejek zapisu, retry logic czy timeoutów.